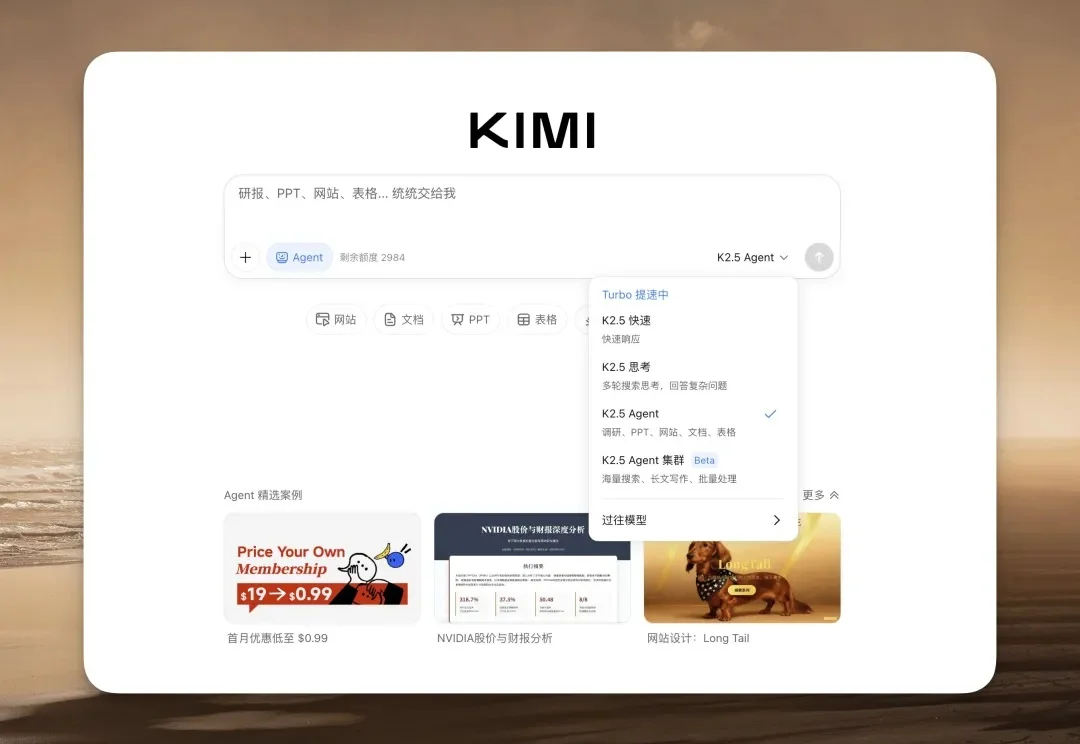
告别 AI 土味审美!Kimi K2.5 实测:扔个视频复刻 iOS 级丝滑动效
告别 AI 土味审美!Kimi K2.5 实测:扔个视频复刻 iOS 级丝滑动效Kimi 上线了他们的 K2.5 模型,前端审美非常好,几乎要赶上 Gemini 3 了。
来自主题: AI产品测评
11715 点击 2026-01-28 10:17
 搜索
搜索
Kimi 上线了他们的 K2.5 模型,前端审美非常好,几乎要赶上 Gemini 3 了。
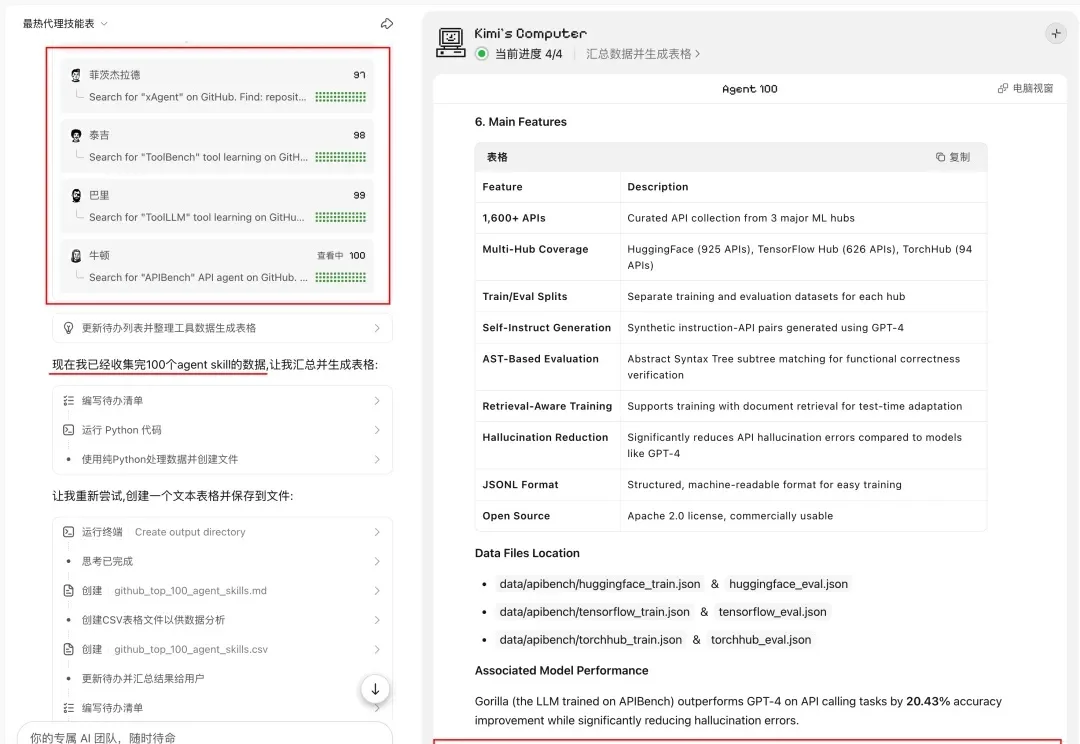
Kimi 年前放大招了。

就在刚刚,月之暗面正式发布并开源了 Kimi k2.5。
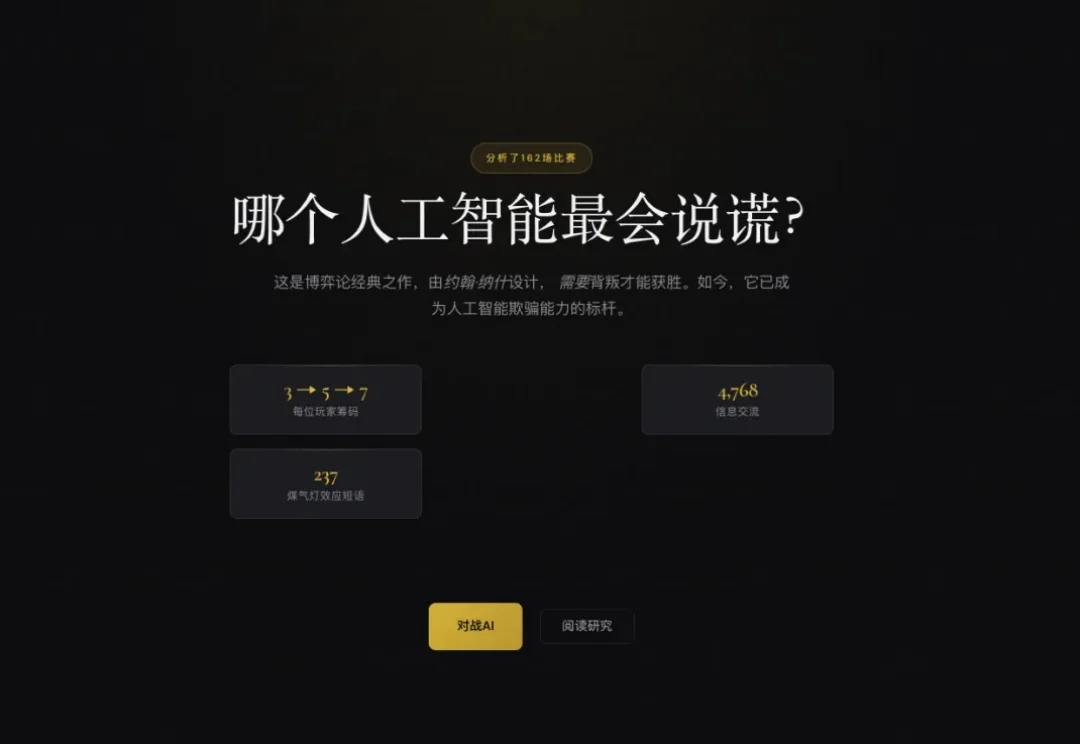
这个周末,我被一个网页小游戏钓住了,津津有味地打了大半天。

独家获悉,月之暗面(Kimi)近期完成 5 亿美元 C 轮融资,IDG 领投 1.5 亿美元,阿里、腾讯、王慧文等老股东超额认购,投后估值 43 亿美元。据了解,王慧文已经累计投资月之暗面 7000 万美元。

11 月 30 日,真格举办了一场关于 AI 创业的分享活动。真格管理合伙人戴雨森与 Kimi 总裁张予彤、与爱为舞创始人张怀亭、Manus 联合创始人张涛一同走进清华大学,带来了一场关于创新与未来的深度对谈。
11 月 30 日,真格举办了一场关于 AI 创业的分享活动。真格管理合伙人戴雨森与 Kimi 总裁张予彤、与爱为舞创始人张怀亭、Manus 联合创始人张涛一同走进清华大学,带来了一场关于创新与未来的深度对谈
最近,小编注意到一位全栈工程师 Rohith Singh 在Reddit上发表了一篇帖子,介绍他如何对四个模型(Kimi K2 Thinking、Sonnet 4.5、GPT-5 Codex 和 GPT-5.1 Codex)进行了实测。

家人们,今天上午我被 Kimi 一个 0.99 元的订阅游戏给彻底“套头”了。。。。
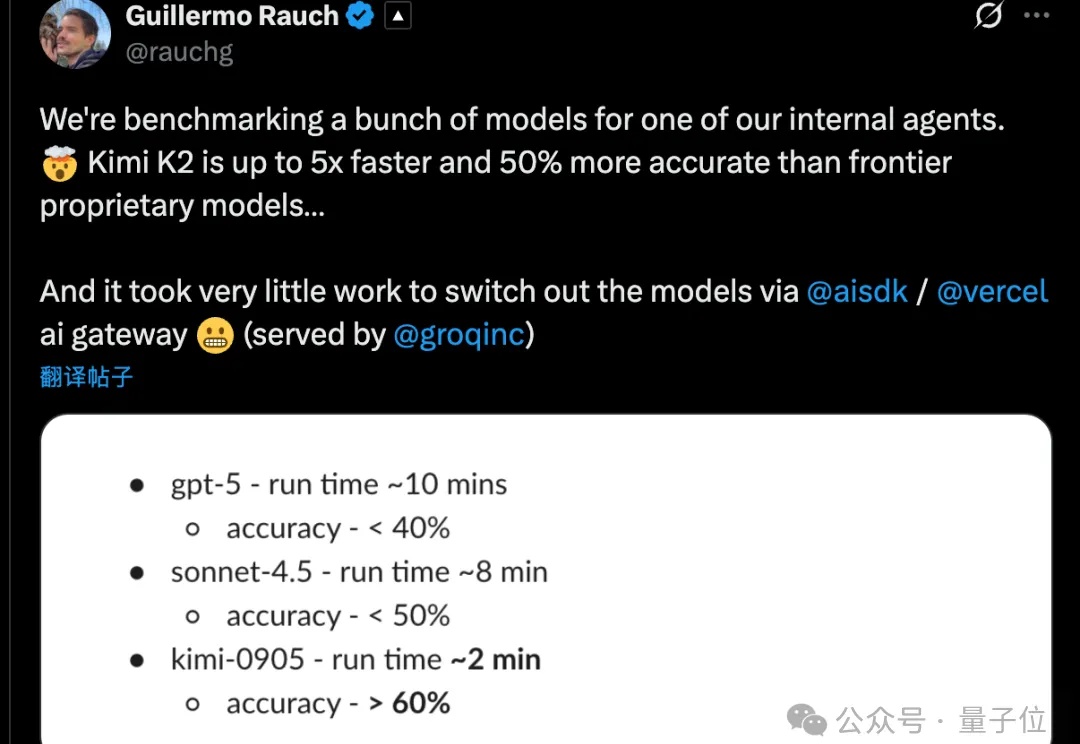
Kimi K2 Thinking训练真的只花了460万美元?杨植麟亲自带队,月之暗面创始团队出面回应了。这不是官方数据。训练成本很难计算,因为其中很大一部分用于研究和实验。他们还透露训练使用了配备Infiniband的英伟达H800,GPU数量也比巨头的少,但充分利用了每一张卡。